At the Intel Vision event, the second generation of Habana AI accelerators was announced: Gaudi2 for deep learning tasks and Greco for inference systems. Both chips are now manufactured using a 7nm process rather than a 16nm process, but that’s far from the only improvement.
Gaudi2 comes in an OAM form factor and has a TDP of 600W. This is almost double the 350 watts that Gaudi had, but the second generation of chips differs significantly from the first. Thus, the amount of on-board memory has tripled; up to 96 GB, and now it’s HBM2e, so as a result, the bandwidth increased from 1 to 2.45 TB / s. The amount of SRAM has doubled to 48 MB. Complementing the memory are DMA engines that can convert data into the desired form on the fly.

Images: Intel/Habana
There are two main types of compute units in Gaudi2: Matrix Multiplication Engine (MME) and Tensor Processor Core (TPC). MME, as the name implies, is designed to speed up matrix multiplication. TPCs are programmable VLIW blocks for working with SIMD operations. TPCs support all popular data formats: FP32, BF16, FP16, FP8, as well as INT32, INT16 and INT8. There are also hardware decoders for HEVC, H.264, VP9 and JPEG.

A feature of Gaudi2 is the possibility of parallel operation of MME and TPC. This, according to the creators, significantly speeds up the process of training models. SynapseAI proprietary software supports integration with TensorFlow and PyTorch, and also offers tools for transferring and optimizing ready-made models and developing new ones, an SDK for TPC, utilities for monitoring and orchestration, etc. However, the richness of the software ecosystem like that of the same NVIDIA is still far away.
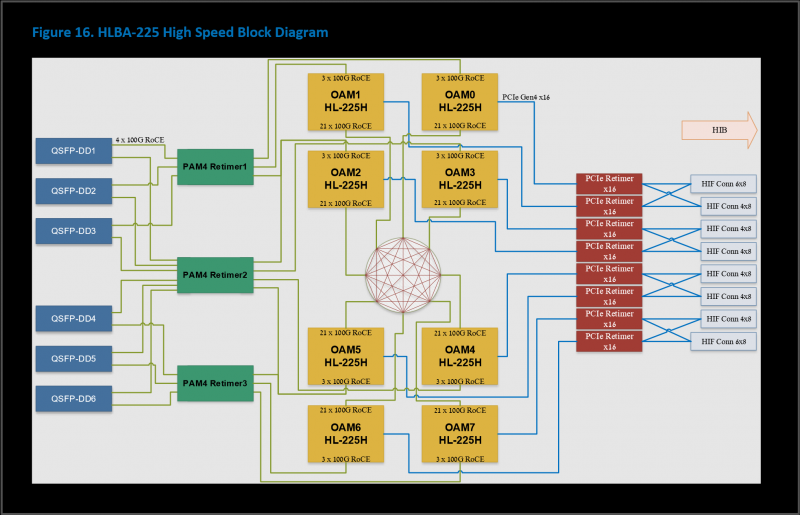
The interface part of the new products includes PCIe 4.0 x16 and immediately 24 (previously there were only 10) 100GbE channels with RDMA ROcE v2, which are used to connect accelerators to each other both within the same node (3 channels each-to-each) and between nodes. Intel offers the HLBA-225 board (OCP UBB) with eight Gaudi2 on board and a ready -made AI platform , still based on Supermicro X12 servers, but with new boards, and DDN AI400X2 storage.
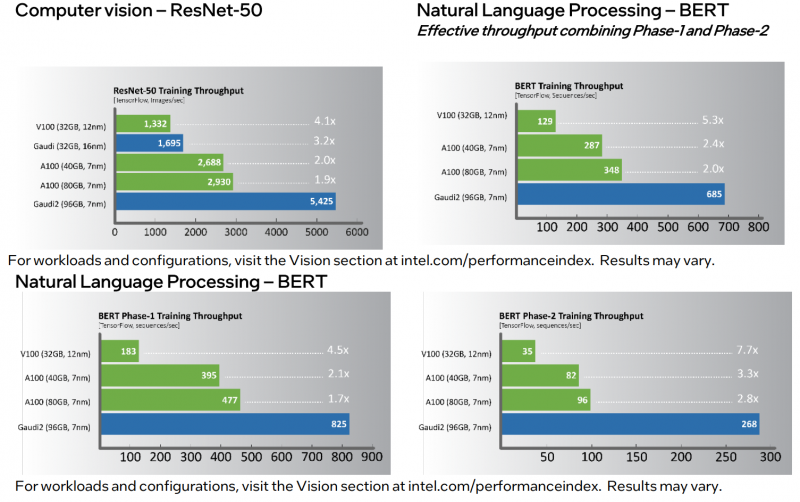
Finally, the most interesting is the performance comparison. In a number of popular workloads, the new product is 1.7–2.8 times faster than the NVIDIA A100 (80 GB) . At first glance, the result is impressive. However, the A100s are far from new. Moreover, the H100 accelerators are expected to be released in the third quarter of this year, which, according to NVIDIA, will be on average three to six times faster than the A100, and thanks to new features, the increase in learning speed can be up to nine times. Well, in general, H100 are more versatile solutions.
Gaudi2 is already available to Habana customers, and several thousand accelerators are used by Intel itself for further software optimization and development of Gaudi3 chips. Greco will be available in the second half of the year, and their mass production is scheduled for the first quarter of 2023, so there is not much information about them yet. For example, it is reported that accelerators have become much less voracious compared to Goya and have reduced TDP from 200 to 75 watts. This allowed them to be packaged in a standard HHHL expansion card with a PCIe 4.0 x8 interface.

The amount of on-board memory is still 16 GB, but the transition from DDR4 to LPDDR5 made it possible to five times increase the bandwidth – from 40 to 204 GB / s. But the chip itself now has 128 MB of SRAM, and not 40 like Goya. It supports BF16, FP16, (U)INT8 and (U)INT4 formats. There are HEVC, H.264, JPEG and P-JPEG codecs on board. The same SynapseAI stack is offered to work with Greco. The company did not provide a comparison of the performance of the novelty with other inference solutions.

However, both Habana’s decisions look a bit belated. The lag on the AI front is probably partly “to blame” for the unsuccessful bet on Nervana solutions – Habana solutions came to replace the unreleased NNP-T accelerators for training, and new NNP-I inference chips should not be expected. Nevertheless, the fate of Habana even inside Intel does not look cloudless, since its solutions will have to compete with Xe server accelerators, and in the case of inference systems, even with Xeon.
Source:





